

Replacing Myself: Writing Unit Tests with ChatGPT
Leveling UpThe Bot that’s got everyone talking The science-fiction future is among us as we find ourselves on the precipice of an AI revolution. As...
One of the realities in programming these days is job mobility. You end up working at different companies on different projects with different people. And they all have different ways of working, individually and with each other. You can focus on the negative (oh my, yet another style guide and work logging procedure) or look for the bright side. I try to focus on the positive, and try to pick up good habits when I’m on a job. I can examine my habits (and assumptions) in that context to see if there are any I should jettison. I can also examine what They’re doing, and see if there’s any good tricks, techniques, or practices I can adopt.
One concept I’ve embraced whole-heartedly is the “experimental directory.” At the job where I learned this, code review was absolutely pervasive. Nothing could be “landed” (checked in to the source code control system to be considered for production use) without a positive code review first. Once the review happened, and you addressed any concerns to the reviewer’s satisfaction, you could commit your code permanently. (you are using source code control, right?)
That kind of sucks for one-offs, experiments, and prototypes, though. What if I’m doing a Spike with a potentially useful library, but I don’t want to mess with the main code base? This kind of stuff is not meant to be run in production, but it’s really nice having them under source code control. Forcing a code review for an experiment in a new API would be a waste of time. “Uh, I dunno George. I’ve never used Gitdown’s Oleginator before. Guess it looks good to me.”
Rather than force all the one-off stuff to be code reviewed, we had an “experimental” directory in the source code system. You’d make a subdirectory in there with your username, and then you’d be able to check stuff in without code review. Say I was playing with iOS gesture recognizers, I could make a new Xcode project and check the stuff into /experimental/markd/gesture-fun. Anything in experimental could be checked in without review.
This experimental directory was visible to everybody. You could noodle on some stuff, and then later on point a coworker to your work. It was fun to just browse to see what people were doing.
One big, big rule: no real development happens in experimental. You can’t use it to bypass regular code reviews. If you decided that your API investigation yielded good results, and it’s time to write the real code, you’d make your edits to the production code and get it reviewed.
That’s all well and good, pretty straightforward happiness and light. I’m sure everybody has a “Projects” directory they throw stuff. It might even be under source code control. Why am I wasting your time here?
I take it a step further. I like putting my experimental projects in the same repository as the actual project. Got a client project, and looking at a new API? The test code goes into an experimental/markd directory in that repo. Got a shared code base? Prototypes and whatnot go into an experimental/markd directory there. During the hours when I’m getting paid to do programming, I’m actually “working for” a bunch of different projects, and a bunch of different clients. These might be paying customers. They might be Ranch-internal projects. They may be other projects in which I’m a major contributor. I have experimental directories in these where I put stuff.
Why not just stash all that stuff in my home directory?
Good question. It’s easy enough to have a github or bitbucket repository that I just toss all of my experimental stuff in to. I tend not to do that because oftentimes someone is paying me for my time when working on a project. The code I write that’s more experimental and might never get put into a production app is still being paid for. I feel the customer should get value out of what they’re paying.
Frequently an experiment might use code elsewhere in the project, whether from my experimental directory, someone else’s experimental directory, or reviewed-and-landed code in the release branch. Pulling in a couple of model objects or a graphics library could be helpful. If you have good dependency management you won’t have to pull in a bunch of extra junk. This existing code might include proprietary code that I wouldn’t want to put into another repository for legal or ethical reasons. I might be limited in where this code can live, perhaps only on encrypted volumes. The client might not want any of their code to even exist on my own machine.
Secondly, I want other programmers on the project to be able to use my experimental work. I might play with a new API with an eye towards how it might be included in the product, but it’s really more “play with it and learn it”. I’d work on that code in my experimental directory. It’d be real easy to tell a team member “check out GridGrooviness in my experimental. Think that’s something worthwhile to pursue?” I can refer to it later. “Six months ago I hacked out something similar. Checkout GridGrooviness in my experimental and see if that’d be useful.” And because programmers are the preferred prey of the average bus, the code I’ve put into a project’s experimental directory is there after my demise, or even if I just leave the team or the company.
Sometimes serendipity can happen too. On one contracting project I was working on, we determined we might need a bit of middleware to simplify access to an awkward web service. I coded a quick prototype (using Flask and Python, for both of you who are terminally curious about such things), and put it in my experimental directory.
Then one of my teammates took the initiative, grabbed the code, cleaned it up, and started expanding it. Once it looked like it’d be something we’d actually use in production, we reviewed the work and put it into its own repository for easy server deployment. Had this thing been relegated to my home directory, or a private project repository, that work might have dead-ended.
So when do I do work in experimental, vs elsewhere? If it’s a new feature, a refactor, or a bug fix, I use whatever workflow our group has (check everything into one branch, or use feature branches and pull requests). If I’m playing with a new API, whether from Apple or a third party, I almost always put my initial playground into my experimental directory.
If I don’t know how a technology works, I don’t want to be blindly experimenting on our real code. I know I’m going to make mistakes (that’s kind of the point). On the other hand, it’s nice having it around. If I discover that yes, I understand how this works, and the prototype I’ve been doing is production caliber, I can move the files into the main line.
Why not a branch for this? Mainly for discoverability and accessibility for other members of our group. It’s easier to say “go look in my experimental” than “pull down this random branch which might not even compile any more.” Plus having a million of little dead-end branches is kind of annoying.
OK, some real-world examples, pulled from actual experimental directories. Here’s a listing of my experimental directory with a group I’ve been working with for a couple of years:
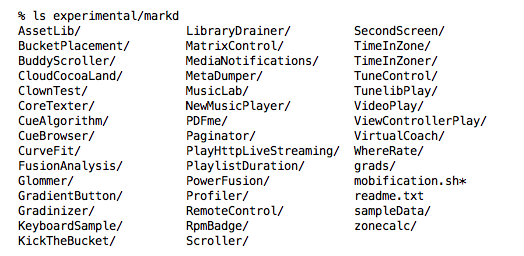
This (iOS) project heavily uses music and playlists, so I have things like “Library Drainer” and “MetaDumper” which extracts a user’s music (and later photo assets) and generates a list of its contents. I gave that to co-workers and friends of the company so I could get a sense of variety of stuff that real users of our apps will have. PlaylistDuration experiments with getting the duration of the playlist, given a number of performance challenges. “NewMusicPlayer” is attempts at making a music playback system that gives us more control than Apple’s built-in stuff. “TuneControl” is a remote control of desktop iTunes from an iPhone.
Another example: I’m working on a team making a content-creation device for the iPad, and part of our workflow involves editing multiple properties on a lot of individual (small) objects. One thought was to have buttons on the edge of the device that you could tweedle with the pad of your thumb while you were holding the device. This is a perfect application of an experimental project. This is the end result:
?
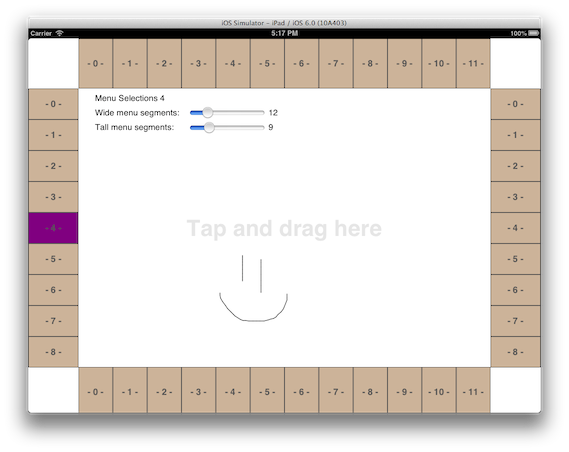
It’s a quick two-hour hack, but we can all now pick it up, play with it, pretend we’re using the app by tapping in the middle part (which just draws your taps and drags), and decide if this actually will work. A throw-away prototype, but because it’s landed with the other code in the project, it’s available for use later. Plus, the customer who paid for my two-hour hack has something to show for it. You can get the source if you want. It’s not stunning code. It’s not great quality. But did let us play with this scenario.
We’ve decided for now not to go with this route – it was uncomfortable for some of our use cases. Good thing we didn’t put this into the main (big) code base. But this prototype code is there in case we need it. If I should move on to another project or get hit by a meteor, this work is not lost. The company may decide at a later date that yeah, we want to revisit this design idea. They won’t have to pay another couple of hours of wages to recreate it.
The takeaways:
Prototype / play /spike / experimental directories are a good thing.
Keep them under source code control
If it’s experimental work for a particular client project, keep it alongside that project. It might be your experiment, but it’s an experiment on behalf of the project, and could have value after your involvement with the project has ended.
The Bot that’s got everyone talking The science-fiction future is among us as we find ourselves on the precipice of an AI revolution. As...

Big Nerd Ranch is chock-full of incredibly talented people. Today, we’re starting a series, Tell Our BNR Story, where folks within our industry share...

Writing documentation is fun—really, really fun. I know some engineers may disagree with me, but as a technical writer, creating quality documentation that will...