


Four Key Reasons to Learn Markdown
Back-End Leveling UpWriting documentation is fun—really, really fun. I know some engineers may disagree with me, but as a technical writer, creating quality documentation that will...
This post was adapted from a talk called “String Theory”, which I co-presented with James Edward Gray II at Elixir & Phoenix Conf 2016.
You may have heard that Elixir has great Unicode support. This makes it a great language for distributed, concurrent, fault-tolerant apps that send poo emoji! 💩
Specifically, Elixir passes all the checks suggested in The String Type is Broken.
The article says that most languages fail at least some of its tests, and mentions C#, C++, Java, JavaScript and Perl as falling short (it doesn’t specify which versions). But here I’ll compare the languages I use most: Elixir (version 1.3.2), Ruby (version 2.4.0-preview1) and JavaScript (run in v8 version 4.6.85.31).
(By the way, the test descriptions use terms like “codepoints” and “normalized”—I’ll explain those later.)
| 1. Reverse of “noël” (e with accent is two codepoints) is “lëon” | |
| Elixir | String.reverse(“noël”) == “lëon” |
| Ruby | “noël”.reverse == “l̈eon” |
| JS | (No built-in string reversal) |
| 2. First three chars of “noël” are “noë” | |
| Elixir | String.slice(“noël”, 0..2) == “noë” |
| Ruby | “noël”[0..2] == “noe” |
| JS | “noël”.substring(0,3) == “noe” |
| 4. Length of “😸😾” is 2 | |
| Elixir | String.length(“😸😾”) == 2 |
| Ruby | “😸😾”.length == 2 |
| JS | “😸😾”.length == 4 |
| 5. Substring after the first character of “😸😾” is “😾” | |
| Elixir | String.slice(“😸😾”, 1..-1) == “😾” |
| Ruby | “😸😾”[1..-1] == “😾” |
| JS | “😸😾”.substr(1) == “😾” |
| 6. reverse of “😸😾” is “😾😸” | |
| Elixir | String.reverse(“😸😾”) == “😾😸” |
| Ruby | “😸😾”.reverse == “😾😸” |
| JS | (No built-in string reversal) |
| 7. “baffle” (“baffle” with ligature – “ffl” as a single code point) upcased should be “BAFFLE” | |
| Elixir | String.upcase(“baffle”) == “BAFFLE” |
| Ruby | “baffle”.upcase == “BAfflE” |
| JS | “baffle”.toUpperCase() == “BAFFLE” |
| 8. “noël” (this time the e with accent is one codepoint) should equal “noël” if normalized | |
| Elixir | String.equivalent?(“noël”, “noël”) == true |
| Ruby | (“noël”.unicode_normalize == “noël”.unicode_normalize) == true |
| JS | (“noël”.normalize() == “noël”.normalize()) == true |
OK, but how does Elixir support Unicode so well? I’m glad you asked! (Ssssh, pretend you asked.) To find out, we need to explore the concepts behind Unicode.
Unicode is pretty awesome, but unfortunately, my first exposure to it was “broken characters on the web.”

To understand Unicode, let’s talk first about ASCII, which is what English-speaking Americans like me might think of as “plain old text.” Here’s what I get when I run man ascii on my machine:

ASCII is just a mapping from characters to numbers. It’s an agreement that capital A can be represented by the number 65, and so on. (Why 65? There are reasons for the numeric choices.) The number assigned to a character is called its “codepoint.”
To “encode” ASCII—to represent it in a way that can be stored or transmitted—is simple. You just convert the codepoint to base 2 and pad it with zeros up to a full 8-bit byte. Here’s how to do that in Elixir:
base_2 = fn (i) ->
Integer.to_string(i, 2)
end
# A ? gives us the codepoint
?a == 97
?a |> base_2.() |> String.pad_leading(8, ["0"]) == "01100001"
Since there are only 128 ASCII characters; their actual data is never more than 7 bits long, hence the leading 0 when we encode ‘a’.
| Character | UTF-8 bytes |
|---|---|
| a | 01100001 |
And that’s fine as far as it goes. But we want to be able to type more than just these characters.
We want to type accented letters.
á é í ó ú ü ñ ź
And Greek letters.
λ φ θ Ω
And this Han character that means “to castrate a fowl.”
𠜎
And sometimes we want to type more than just words. Sometimes we want to type pictures.
𠜎 = 🐓 + 🗡
We want to type emoji for laughing, and crying, and kissing, and being upside down, and having dollars in our mouths.
😆 😭 😘 🙃 🤑
Unicode lets us type them all. Unicode lets us type anything in all of human language. In theory.
In practice, Unicode is made by a standards body, so it’s a political process, and some people say that their language isn’t getting a fair shake. For example, in an article called I Can Text You A Pile of Poo, But I Can’t Write My Name, Aditya Mukerjee explains that Bengali, with about 200 million native speakers (more than Russian), can’t always be properly typed on a computer.
Similarly, through something called the “Han unification,” people who type Chinese, Japanese and Korean have been told, “hey listen, y’all are gonna have to share some of your characters to save space.”

Or at least, that’s how some of them interpret it. There is an article on the Unicode site explaining the linguistic, historical and technical rationale, which also says:
This process was well-understood by the actual national standards participants from Japan, Korea, China, and other countries, who all along have been doing the major work involved in minimizing the amount of duplicate encoding of what all the committee members fully agree is the same character.
As someone who doesn’t write any of the languages in question, I can’t really weigh in. But if saving space was part of the rationale, it does seem odd that Unicode has seen fit to include playing cards…
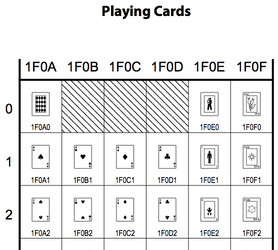
…and alchemical symbols…

…and ancient Greek musical notation…

…oh, and Linear B, which nobody has used for anything for several thousand years.
But for the purposes of this article, what’s important is that Unicode can theoretically support anything we want to type in any language.
At its core, Unicode is like ASCII: a list of characters that people want to type into a computer. Every character gets a numeric codepoint, whether it’s capital A, lowercase lambda, or “man in business suit levitating.”
A = 65
λ = 923
🕴= 128,372 # <- best emoji ever
So Unicode says things like, “Allright, this character exists, we assigned it an official name and a codepoint, here are its lowercase or uppercase equivalents (if any), and here’s a picture of what it could look like. Font designers, it’s up to you to draw this in your font if you want to.”
Just like ASCII, Unicode strings (imagine “codepoint 121, codepoint 111…”) have to be encoded to ones and zeros before you can store or transmit them. But unlike ASCII, Unicode has more than a million possible codepoints, so they can’t possibly all fit in one byte. And unlike ASCII, there’s no One True Way to encode it.
What can we do? One idea would be to always use, say, 3 bytes per character. That would be nice for string traversal, because the 3rd codepoint in a string would always start at the 9th byte. But it would be inefficient when it comes to storage space and bandwidth.
Instead, the most common solution is an encoding called UTF-8.
UTF-8 gives you four templates to choose from: a one-byte template, a two-byte template, a three-byte template, and a four-byte template.
0xxxxxxx 110xxxxx 10xxxxxx 1110xxxx 10xxxxxx 10xxxxxx 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Each of those templates has some headers which are always the same (shown here in red) and some slots where your codepoint data can go (shown here as “x”s).
The four-byte template gives us 21 bits for our data, which would let us represent 2,097,151 different values. There are only about 128,000 codepoints right now, so UTF-8 can easily encode any Unicode codepoint for the foreseeable future.
To use these templates, you first take the codepoint you want to encode and represent it as bits.
For example, ⏰ is codepoint 9200, as we can see by using ? in iex.
?⏰ # => 9200
Now let’s see that number in base 2:
base_2.(?⏰) == "10001111110000"
That’s 14 bits long—too many to fit into the UTF-8 2-byte template, but not too many for the 3-byte template. We insert them into it right to left, and pad with leading zeros.

Is this what Elixir actually does? Let’s use the handy IEx.Helpers.i/1 function to inspect a string containing ⏰ in iex:
i "⏰"
....
Raw representation
<<226, 143, 176>>
This shows us that the string is actually a binary containing three bytes. In Elixir, a “bitstring” is anything between << and >> markers, and it contains a contiguous series of bits in memory. If there happen to be 8 of those bits, or 16, or any other number divisible by 8, we call that bitstring a “binary” – a series of bytes. And if those bytes are valid UTF-8, we call that binary a “string”.
The three numbers shown here are decimal representations of the three bytes in this binary. What if we convert them to base 2?
[226, 143, 176] |> Enum.map(base_2)
# => ["11100010", "10001111", "10110000"]
Yep, that’s the UTF-8 we expected!
UTF-8 is cool because you can look at a byte and tell immediately what kind it is, based on what it starts with. There are “solo” bytes (as in, “this byte contains the whole codepoint”) which start with 0, “leading” bytes (the first of several in a codepoint) which start with 11 (and possibly some more 1s after that), and “continuation” bytes (additional bytes in a codepoint) which start with 10. The leading byte tells you how many continuation bytes to expect: if it starts with 110, you know there are two bytes in the codepoint; if 1110, there are three bytes in the codepoint, etc.
| Starts With | Kind |
|---|---|
| 0 | Solo |
| 10 | Continuation |
| 110 or 1110 or 11110 | First of N (count the 1s) |
Here’s an example character for each of the UTF-8 templates.
| Character | UTF-8 bytes |
|---|---|
| a | 01100001 |
| ë | 11000011 10101011 |
| ™ | 11100010 10000100 10100010 |
| 🍠 | 11110000 10011111 10001101 10100000 |
The letter ‘a’ is encoded with a solo byte—a single byte starting with 0. The “roasted sweet potato” symbol has a leading byte that starts with four 1s, which tells us that it’s four bytes long, then three continuation bytes that each start with 10.
Also, notice that the encoding for ‘a’ looks exactly like ASCII. In fact, any valid ASCII text can also be interpreted as UTF-8, which means that if you have some existing ASCII text, you can just declare “OK, this is UTF-8 now” and start adding Unicode characters.
The fact that each kind of byte looks different means you could start reading some UTF-8 in the middle of a file or a stream of data, and if you landed in the middle of a character, you’d know to skip ahead to the next leading or solo byte.
It also that means that you can reliably do things like reverse a string without breaking up its characters, measure the length of a string, or get substrings by index. In my next post, we’ll see how Elixir does those things. We’ll also learn why “noël” isn’t the same as “noël”, how to write comments that break a web site’s layout, and why even Elixir won’t properly downcase “ΦΒΣ”.
Writing documentation is fun—really, really fun. I know some engineers may disagree with me, but as a technical writer, creating quality documentation that will...
Humanity has come a long way in its technological journey. We have reached the cusp of an age in which the concepts we have...

Go 1.18 has finally landed, and with it comes its own flavor of generics. In a previous post, we went over the accepted proposal and dove...