

Swift Regex Deep Dive
iOS MacOur introductory guide to Swift Regex. Learn regular expressions in Swift including RegexBuilder examples and strongly-typed captures.
Want to learn more about what’s really happening inside those square brackets? Read the entire Inside the Bracket series.
What is something that we use every day as a Mac or iOS programmer? Objective-C. What do we use every day in Objective-C? Those square brackets. How many times a day do you type something like this?
[someObject doSome:stuff for:reasons];
Ever wondered what’s really happening inside those square brackets? Polymorphism!
Great. Fancy words. Thank you! As every Introduction to Object-Oriented Programming book tells you, polymorphism comes from the Greek words “poly”, meaning “many”, and “morph”, meaning shapes. We have a bunch of shapes (a pile of assorted Lego bricks). Or, it can mean we have something that can take on many shapes (a Lego brick that can change from a 2×2 into a 1×4.). These days it pretty much means “I’m sending a message to an object, and the behavior caused by that message will happen. But I don’t really create precisely what it does.” You can ask an NSArray its count. You can ask an NSSet its count. The implementation of -count can be radically different between the two, but you get each one’s count by sending the same message. What problem is it solving, though? Why have polymorphism? Back in the Old Days of contrived programming straw-men (straw-persons?), you might be implementing a graphical toolkit, and you might have code like this which draws all the views in a window:
void DrawViews (View *views[], int count) {
for (int i = 0; i < count; i++) {
View *view = views[i];
switch (view->kind) {
case kButtonView:
printf ("Drawing a button!n");
ButtonDraw (view);
break;
case kSliderView:
printf ("Drawing a slider!n");
SliderDraw (view);
break;
case kPonyView:
printf ("OMG PONIES!n");
PonyDraw (view);
break;
}
}
} // DrawViews
Where views is an array of pointers to Views, which a “kind” flag to tell what kind of view is what:
typedef struct View {
ViewKind kind;
Rect bounds;
} View;
The Kind is just an enum:
typedef enum {
kButtonView,
kSliderView,
kPonyView
} ViewKind;
It’s pretty readable. You could ship this and not feel sad. The problem comes when you need to update the software, say by adding an Image View. You’d need to touch the ViewKind enum, add an ImageDraw function (which isn’t too bad), and also add a new case to DrawViews. If you had other code (hit-test view) that used views, you’d need to update that code as well. That’s actually bad. Would anyone actually design code like this? Not really. But it does highlight the Open/Closed principle (invented by Bertrand Meyer, and later evangelized by Robert C. Martin). Robust code should be open to extension but closed to modification. It’d be nice to write DrawViews once in such a way where we could add new kinds of views (open) without doing violence to the code that makes the views draw (closed). Something like this pseudocode:
void DrawViews (View *views, int count) {
for (int i = 0; i < count; i++) {
View *view = views[i];
<strong>YoViewDrawYourself</strong> (view);
}
} // DrawViews
If Only We Had that YoViewDrawYourself, that no matter what view is passed in, it could figure out what the code behind the view is. Why is that good? Bugs tend to congregate where code changes happen. Got a weird bug? Oftentimes the most recent code change either introduced it or exposed it. Touching a central loop like DrawViews every time we add a new kind of view is courting disaster. Maybe your wife’s brother’s second cousin who “Knows how to program those phone things” isn’t the world’s greatest software enginerd. Do you want him messing with one of the most-called routines in your toolkit?
A truism in the programming biz is “any problem can be solved by adding a layer of indirection.” Of course, this doesn’t mean that adding a layer of indirection is the only solution, or the best solution, but a lot of times it’s true. Especially in a case like this: rather than having DrawViews call functions directly, we add a bit of indirection. Instead of using the function name, bounce off a function pointer. Where would be a good place for that function pointer? Put it in with the view. Let’s make the views a little more interesting. They can be drawn, hit-tested, and described. Here’s some function pointers types that describe the different features:
typedef void (*<strong>DrawCallback</strong>) (View *view);
typedef bool (*<strong>HitTestCallback</strong>) (View *view, Point mouseClick);
typedef char * (*<strong>DebugDescriptionCallback</strong>) (View *view);
C function pointer syntax is kind of annoying. The name of the pointer type is in bold here. The the return type is to the left, and the stuff on the right are the arguments to the function. Thus, DrawCallback is a pointer to a function that takes a View pointer, and returns nothing. HitTestCallback takes a View and a Point, and returns true or false if the mouse click is inside or outside of the view. Actually using function pointers is pretty easy. Once you have them typedef’d, you can assign them. Here’s a function that corresponds to the DrawCallback signature:
static void ButtonDraw (View *view) {
printf ("Drawing a button!n");
}
You can have a variable that points to the function:
DrawCallback drawer = ButtonDraw;
Notice ButtonDraw doesn’t have any parens after it here. A paren-less function means “give me the address of the function, where the object code lives in memory, but don’t call it.” You jump through the function pointer by adding arguments (if there are any) in parentheses:
drawer (someView);
This will call ButtonDraw, passing it someView. It is effectively identical to calling ButtonDraw directly except you’re bouncing off of a variable—adding that little bit of indirection.
So, back to view drawing. How can you use these function pointer types to your advantage? If you can put a table of function pointers at a well-known location in a View, DrawViews can find each view’s individual DrawCallback and call it. A common term for such a list of function pointers is a “virtual method table”, or vtable for short. Here’s the vtable for Views:
typedef struct ViewVTable {
DrawCallback draw;
HitTestCallback hitTest;
DebugDescriptionCallback description;
} ViewVTable;
It’s just a struct with three function pointers. Buttons will have draw, hitTest, and description functions:
static void ButtonDraw (View *view) {
printf ("Drawing a button!n");
}
static bool ButtonHitTest (View *view, Point point) {
printf ("Hit testing a button!n");
return false;
}
static char * ButtonDebugDescription (View *view) {
static char s_unsafeBuffer[1024];
snprintf (s_unsafeBuffer, sizeof(s_unsafeBuffer), "Button at %p", view);
return s_unsafeBuffer;
}
And Slider will have a similar set of functions. Here’s the draw:
static void SliderDraw (View *view) {
printf ("Drawing a slider!n");
}
Rather than having a view type constant, replace it with the vtable:
typedef struct View {
ViewVTable vtable;
Rect bounds;
} View;
Here’s what the object looks like in memory once everything is populated.
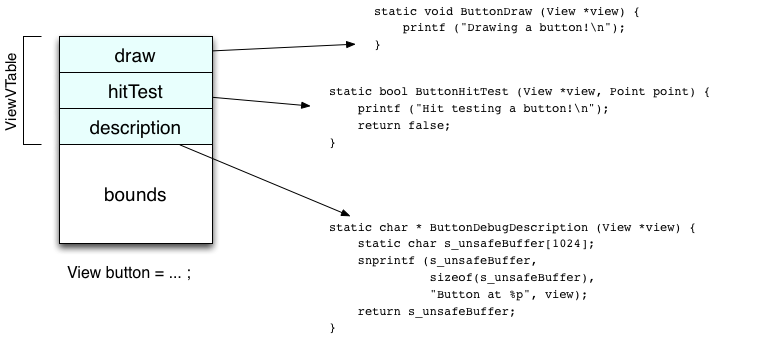
(Side note—the function pointers are duplicated in each View. For realsies, you’d construct a table once in memory, and have Views point to that table.) Setting up the button is pretty easy:
View button;
button.vtable.draw = ButtonDraw;
button.vtable.hitTest = ButtonHitTest;
button.vtable.description = ButtonDebugDescription;
button.bounds = (Rect) { 0.0, 0.0, 100.0, 200.0 };
Just assign the functions-that-do-stuff to the corresponding function pointers.
So, that’s a lot of work and kind of weird indirection. What does it buy us? Here’s an updated DrawViews:
void DrawViews (View *views[], int count) {
for (int i = 0; i < count; i++) {
View *view = views[i];
printf ("drawing %sn",
view->vtable.description(view));
view->vtable.draw (view);
}
} // DrawViews
It takes an array of View pointers and a count, and then chugs through the views, fishing out the description and draw function pointers and jumping through them. Running our button through this function yields:
View *views[] = { &button };
DrawViews (views, 1);
drawing Button at 0x7fff6ad6e720
Drawing a button!
So, does this version of DrawViews adhere to the Open/Closed principle? Let’s check. First, openness—how do you extend it with other view types? Add a slider. First, some functions to do the slidery stuff:
static void SliderDraw (View *view) {
printf ("Drawing a slider!n");
}
static bool SliderHitTest (View *view, Point point) {
printf ("Hit testing a slider!n");
return false;
}
static char * SliderDebugDescription (View *view) {
static char s_unsafeBuffer[1024];
snprintf (s_unsafeBuffer, sizeof(s_unsafeBuffer), "Slider at %p", view);
return s_unsafeBuffer;
}
Populate a View with these function pointers:
View slider;
slider.vtable.draw = SliderDraw;
slider.vtable.hitTest = SliderHitTest;
slider.vtable.description = SliderDebugDescription;
button.bounds = (Rect) { 150.0, 77.0, 300.0, 32.0 };
Call DrawViews:
View *views[] = { &button, &slider };
DrawViews (views, 2);
And get this output:
drawing Button at 0x7fff6ad6e720
Drawing a button!
drawing Slider at 0x7fff6ad6e6f8
Drawing a slider!
So, we’ve added a new View type, so DrawViews is open to extension. Now for closed-ness. You added a slider, but didn’t have to touch DrawViews. That means it’s closed to modification. Looks like a Win. In case you didn’t notice, View can be thought of as a class, with draw, hitTest, and description being methods of that class. An individual View struct floating around memory is an instance of that class.
This model, using vtables, is similar to what C++ does, as well as any number of do-your-own-OOP toolkits written in straight C. It’s very fast. Just pointer+offset to get a function pointer (in this case), or pointer+offset to get the vtable, and then another pointer+offset to get the actual function (when you have your vtable separate from the object). Still, that’s very fast. The tradeoff in speed is flexibility. The vtables are defined at compile time, whether manually like with the Views, or by the compiler. The offsets from the table pointers are baked-in at compile time too, making it problematic to upgrade libraries without requiring a recompile. (This is similar to the Fragile Base Class Problem.) Objective-C takes a different approach. Rather than just having a pile of function pointers, it has a dictionary of function pointers, stored under a name. That doesn’t sound like a big difference. Instead of invoking a view’s drawing code with someView.vtable.draw, you’d actually do someView.dictionary.GetFunctionPointerForName("draw");
Turns out this is a massive difference in behavior. It adds another layer of indirection. Using a function pointer is one layer of indirection. Now the function pointer lookup is another layer of indirection. The big thing is it’s deferring the decision “where do I look for the function to draw with” from compile time (pointer + offset in a struct) to run time (grovel around in a dictionary). You trade some efficiency and safety (e.g. a C++ compiler will guarantee that any View will implement draw) for flexibility.
What is this added flexibility? It has two aspects. The first is you can ask an object questions. “Do you know how to draw?” or “Do you know how to hit test?” or “Can you be a Table View data source?”. This is a familiar operation if you’ve ever used -respondsToSelector. The second aspect is you can change stuff. “Hey Button, even though you didn’t know how to animate a badger running across the screen, here’s a function you should store under the name badgerRunningAcrossScreen.” This is familiar if you’ve ever used categories.
Why can’t we do that stuff using a vtable-style way of finding implementations? All of the interesting information about “Button’s DrawCallback is implemented by the static function ButtonDraw” is gone. If you recall the discussion on symbol visibility, static functions lose identity. There’s no way you can ask “is ButtonDraw used anywhere?” Similarly, assignments to the ViewVTable, and subsequent access, are all pointer+offset. The compiler doesn’t care any more that “DrawCallback” is the first entry in the table. Also, if you have two different “objects” with different vtable layouts—say draw is the first function pointer in View’s vtable, and draw is the last function pointer in Cowboy’s vtable, there’s no way of saying “hey, here’s an arbitrary vtable, give me the one that has a struct element named draw.”
Because Objective-C defers the “draw -> someFunction” mapping til runtime, it can expose all sorts of interesting information (a.k.a. metadata). Walk up to any Objective-C object and ask it “Hey do you -draw?”. The runtime will then look at the object, grab the pile of name-to-function maps, and see if draw is in there. If so, it’ll return YES. This is what allows us to have delegates and data sources that aren’t members of a particular subclass.
Languages like C++ require you to declare a particular class/template heritage for delegate objects so it can place the delegate function pointers at knowable places in the vtable, as well as guarantee that you can call those functions without worrying that they might not be implemented and crashing at runtime. One of the favorite never-ending programming discussions you’ll find is the suck/rule status of both of these approaches. The C++ way is faster and safer, but not as flexible. The Objective-C way is slower but flexible, but you can die unexpected horrible deaths at runtime. Objective-C is what it is, so I won’t get into this discussion.
OK, after that fascinating (eye-roll) discussion of polymorphism strategies, how does that apply to this line of Objective-C code:
[someObject doSome:stuff for:reasons];
This says : look at someObject. Find its bag of name->function mappings. Look for doSome:for: in the bag. If found, call that code. (Another aside : There’s the whole additional world of inheritance which I haven’t touched on. Subclasses in vtable language just copy the superclass’s function pointers. There’s no penalty if you invoke a member function that’s implemented in a superclass. It’s still pointer + offset + jump. Objective-C, if it can’t find a method implementation, will look at the bag of name->function mappings of the superclass if it can’t find an implementation of the object that got sent a message.) How does this work under the hood? All Objective-C objects have a pointer in a well-known offset from the beginning of the object, called **isa**. This is a pointer to a “class object”, which you can think of as the bag of name->function mappings, a pointer to the superclass, and the metadata for the class. Want to send -doSome:for: to an object? Grab that object’s isa, look up -doSome:for: in the bag, and jump to that code.
Objective-C, in its first incarnations, was not a stand-alone compiler. It was a preprocessor that read your .m files and emitted C code, which would then get compiled by a C compiler. There was a runtime component that would take objects, pointer+offset them to get the isa pointer, and then look up function pointers. This preprocessor would turn bracketed calls:
[someObject doSome:stuff for:reasons];
into calls to objc_msgSend:
objc_msgSend (someObject, @selector(doSome:for:), stuff, reasons);
objc_msgSend is where all the lookup work happens. Nowadays, the compiler doesn’t have to go through a C intermediary, instead it can emit objc_msgSend directly. Don’t believe me? You can always look at what the compiler is emitting:
int main (void) {
@autoreleasepool {
SomeObject *obj = [[SomeObject alloc] init];
[obj doSome: @"stuff" for: @"reasons"];
}
return 0;
} // main
Run it through a disassembler, and see that it’s the case:

You can see it putting obj (var_32) and the selector, along with @”stuff” (var_16) and @”reasons” (var_8) into place, and then finally calling objc_msgSend at the end. objc_msgSend is a brilliant piece of engineering, a real example of the power and utility of a little bit of hand-crafted assembly language in the right spot. Bill Bumgarner has a dissection of objc_msgSend as it existed in OS X 10.6, and since then it’s been optimized even more.
That’s a lot of concepts and detail. What do we know now about this code now?
[someObject doSome:stuff for:reasons];
And why is it going going through all of these gyrations to look up a function to call? Amongst lots of other things, it gives us that layer of abstraction that lets us write code that adheres to the Open/Closed principle. The caller of someObject doesn’t care what actually happens when it’s asked to do stuff, so long as it does it. By hiding the details behind this layer of abstraction, it allows the code sending this message to operate at a higher, more abstract level. We now have flexibility to have core code working on abstract entities to not worry about the details, allowing more flexible (if sometimes harder to follow) code and architectures. Up next, into the Objective-C runtime.
Our introductory guide to Swift Regex. Learn regular expressions in Swift including RegexBuilder examples and strongly-typed captures.

The Combine framework in Swift is a powerful declarative API for the asynchronous processing of values over time. It takes full advantage of Swift...

SwiftUI has changed a great many things about how developers create applications for iOS, and not just in the way we lay out our...